一般有兩種特殊的命名法則,分別是匈牙利命名法和駱駝命名法。所謂匈牙利命名法,就是在名稱的前面,加上該物件類別的縮寫,這樣我們只要看到名稱就可以知道它是屬於哪一種的物件。例如有一張圖片的名稱本來叫做「MyPhoto」,我們在前面加上縮寫變成「imgMyPhoto」,這樣一看就知道它其實是個 <img> 元件的名字。而駱駝命名法,則像前面一樣,它是將復合的英文字母連貫起來,並且在分隔的地方以大寫、其餘處用小寫來命名。例如我原本也可以寫成「img_my_photo」,但是這樣就顯得拉長了許多,因此寫成「imgMyPhoto」一則節省空間,一則也容易閱讀。
匈牙利命名法(Hungarian Notation)
匈牙利命名法是微軟程式設計師Charles Simonyi發明的。Simonyi在微軟做的主要計劃是Word;事實上他還主持了世界上第一個所見即所得的文書處理器(在Xerox Parc名為Bravo計劃)。 在所見即所得的文書處理中會用到可捲動的視窗,所以座標值有兩種意義:相對於視窗或相對於處理頁。兩種座標的差異很大,所以好好安排是非常重要的。 我猜這正是Simonyi開始採用某些之後被稱作匈牙利命名法的原因之一。它看起來像匈牙利文,而Simonyi是從匈牙利來,所以以匈牙利為名。在Simonyi版本的匈牙利命名法中,每個變數都會加一個小寫的字首,表示變數內容的種類。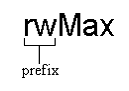
在這故意用種類(kind)這個詞,因為Simonyi在他的文章中誤用了型別(type),結果好幾世代的程式師都誤解了他的意思。
在這我們使用us和s分別定義為不安全字串和安全字串。這兩者的型別都是字串。如果你把某種字串指派另一種,編譯器並不會給任何警告, Intellisense也不會說些什麼。可是他們的語意是不同的;他們解讀和處理的方式都不同,要把兩種字串互相指派時還要某些轉換函數做轉換,否則就會有執行時期的問題。
微軟內部稱Simonyi對匈牙利命名法的原始概念為應用匈牙利命名法,因為它用於應用程式部門,也就是Word及Excel。在Excel的原始程式碼裡有大量的rw和col,你看到這些字首就知道它們指的是行(row)和列(column)。沒錯,它們都是整數,可是兩者間的轉換完全沒有意義。有人告訴我說Word的程式碼裡有大量的xl和xw, xl代表相對於排版頁面的水平座標,而 xw則代表相對視窗的水平座標。兩者都是整數但卻是不能互轉的。兩個程式裡都有很多cb,意思是位元組的個數。沒錯,這也是整數型別,不過光看變數名就可以得到更多資訊:這是位元組的個數,也就是緩衝區的大小。另外如果你看到xl = cb就可以拉警報了。這顯然是錯的程式,雖然xl和cb都是整數, 可是把以像素為單位的水平位移設成位元組個數絕對是瘋了。
在應用匈牙利命名法中字首可以用於函數和變數。因此雖然我真的沒看過Word的原始碼,我還是敢打賭Word裡一定有個叫YlFromYw的函數,可以把垂直方向的視窗座標轉成垂直方向的排版頁座標。應用匈牙利命名法用TypeFromType取代傳統的 TypeToType,這樣每個函數名就會以傳回的型別開頭, 這正與我稍早在範例中把Encode改名為SFromUs的作法相同。事實上在正規的應用匈牙利命名法中Encode函數一定要改名為SFromUs。應用匈牙利命名法在該函數命名上並沒有提供其他選擇。這其實是件好事,因為你少一件事要背,另外也不必擔心Encode究竟是用什麼型別。程式也變得精確多了。
應用匈牙利命名法非常有用,特別是當初C語言盛行,而編譯器尚未提供很有用的型別系統時。
黑暗世界占用了匈牙利命名法
不過接下來卻出了一些問題,黑暗世界占用了匈牙利命名法。似乎沒有人知道為什麼或是如何發生的, 不過似乎是視窗團隊中寫文件的人不小心創造出後來名為系統匈牙利命名法的東西。
某處有人讀了Simonyi的文章看到裡面用了"型別"這個字眼, 因此認為作者指的就是型別,意思就像是類別或是型別系統中, 或是編譯器所做的型別檢查。其實不然。作者很小心並精確的解釋他用"型別"這個字的意義, 不過沒有用。傷害已經造成了。
應用匈牙利命名法的字首很有用而且有意義,"ix"表示陣列索引,"c"表示個數, "d"表示兩個數字間的差(比如"dx"表示"寬度"), 如此類推。
系統匈牙利命名法的字首作用就差多了,"l"表示長整數,"ul"表示正長整數而"dw"代表雙字組(呃,事實上就是正長整數)。在系統匈牙利命名法中,字首只能告訴你變數真正的資料型別。
這誤解了Simonyi的意圖和實作,差異雖細微實質上卻是完全不同。這件事唯一的教訓是讓你知道,如果你寫出些沒人能懂的艱深難解學術文章,你的想法可能會一再被誤解,結果變得非常荒謬,完全違背你的原意。所以在系統匈牙利命名法中會出現大量的dwFoo表示"雙字組的某某",可惡的是某個變數是雙字組這件事對你幾乎是完全沒用的。難怪大家都很討厭系統匈牙利命名法。
系統匈牙利命名法的流傳既深又廣; 它是整個視窗程式設計文件的標準;Charles Petzold的視窗程式設計(學習視窗程式設計的聖經)等書籍更為它廣為宣揚,很快的它也成為匈牙利命名法的主要勢力,即使在微軟內部也一樣。在微軟內也只有少數不在Word和Excel團隊的程式師瞭解他們搞出什麼樣的錯。
接下來就是大反抗了。有群程式師們從一開始就沒搞懂過匈牙利命名法,他們發現自己用的竟是煩人又幾近無用的分支,於是就起來反抗。不過系統匈牙利命名法裡還是有些好東西可以幫你看出問題。如果用系統匈牙利命名法,至少會在使用時知道變數型別。不過沒應用匈牙利命名法那麼有價值就是了。
大反抗在.NET。第一版發行時到達巔峰,那時微軟終於告訴大家「不建議使用匈牙利命名法」。這還真是歡聲雷動啊。 我根本不認為微軟會花心思解釋原因。他們只是掃瞄文件中命名指引的章節然後加上「不要使用匈牙利命名法」的字句。當時匈牙利命名法非常不受歡迎所以沒有人會真的抱怨,而除Excel及Word以外的人都因為不必再用這麼麻煩的命名規範而鬆了一口氣,他們認為在有強型別檢查及Intellisense的時代也不需要這種規範。
匈牙利命名法的使用
匈牙利命名法關鍵是:標識符的名字以一個或者多個小寫字母開頭作為字首;字首之後的是首字母大寫的一個單詞或多個單詞組合,該單詞要指明變數的用途。
在編程時,變數、函數的命名是一個極其重要的問題。好的命名方法使變數易於記憶且程式可讀性大大提高。Microsoft採用匈牙利命名法來命名Windows API函數和變數。匈牙利命名法是由Microsoft的著名開發人員、Excel的主要設計者Charles Simonyi在他的博士論文中提出來的,由於他的國籍是匈牙利,所以這種命名法叫匈牙利命名法。
匈牙利命名法為C識別字的命名定義了一種非常標準化的方式,這種命名方式是以兩條規則為基礎:
1.識別字的名字以一個或者多個小寫字母開頭,用這些字母來指定資料類型。
2.在識別字內,首碼以後就是一個或者多個第一個字母大寫的單詞,這些單詞清楚地指出了源代碼內那個物件的用途。比如,m_szStudentName表示一個學生名字的類成員變數,資料類型是字串型。
變數名稱 = 屬性+類型+描述
屬性
- g_ 全域變數
- c_ 常數
- m_ 成員變數
類型
- n int
- l long
- sh short
- f float
- d double
- ld long double
- c char
- b boolean
- p pointer
- h handle
在變數前面加上該變數的型別,例如:
int iCount;
char szName[100];
整數型別就加上個 "i";以 NULL 字元結尾的字串就加上個 "sz"。C 語言中的基本型別並不多,因此對於程式設計師來說,使用這個命名法也不會太麻煩。隨著 Windows 的普及,在 Win32 中大量導入 Handle 的概念,視窗有視窗的 handle(HWND),Process 有 Process 的 handle(HANDLE)。為了要區別這些變數,開始有人建議在這些變數也加上前綴字元,於是就出現這樣的變數:
HWND hwndMainWin;
HANDLE hProcess;
好吧,就算是再加入這幾種型別也還在程式設計師的記憶體範圍內,大家也都還能接受,於是匈牙利命名法著實風光了一陣子。然而隨著 C++ 的出現,匈牙利命名法受到史無前例的挑戰。
在 OOP 中,自訂型別是一項很重要的特徵。你可以將資料及處理邏輯封裝在一起,成為一種新的型別,並且可以跟基本的型別或其他自訂的型別作運算。一時間,大量的型別冒了出來,突然間程式設計師不知道要如何來命名他的變數。像是一個用來封裝 Windows 基本控制項的 Button 類別,我們可能會這樣寫
CButton btnButton1;
高明的程式設計師會用這個類別的縮寫來做前綴字元,這通常不會使用超過三個字。有些人看到這樣的命名法可能會覺得怪怪的,變數名稱 "Button1" 不就說明它是一個 Button 類別了嗎,就算不是直接從CButton來,我們也可以預期它的動作是和 CButton一樣,那為什麼還要加上個前綴字元來減少鍵盤按鍵的壽命呢?
為了要讓這些人心服口服,因此我們不再使用像 Button1 這樣白癡的命名方式(然而幾乎所有的 RAID 工具都是產生這樣的名字),我們把 Button1 依照他的功能來命名。
CButton btnOk;
CListCtrl listFile;
因此我們可以知道 btnOk 是個會產生 IDOK 訊息的 Button,而 listFile 則是個能顯示一堆檔案的列表元件。故事到此好像就風平浪靜,匈牙利命名法似乎也在 C++ 取得一片天。過了不久,就像國王的新衣故事中最後的小孩一樣,有人開始提出了質疑,為什麼不能用這樣的命名就好:
CButton OkBtn;
CListCtrl FileListCtrl;
雖然只是把前綴字元擺到後面去,但是閱讀起來似乎也還有那麼一點人性。
常用的命名規則
變數(還包括巨集)的命名規則,比較系統和徹底的有Windows編程中用到的匈牙利命名法。匈牙利命名法通過在變數名前面加上相應的小寫字母的符號標識作為首碼,標識出變數的作用域,類型等。這些符號可以多個同時使用,順序是先m_(成員變數),再指標,再簡單資料類型,再其他。例如:m_lpszStr, 表示指向一個以0字元結尾的字串的長指標成員變數。
有關匈牙利命名法的一點有意思的說明是它的名字的由來。這種命名技術是由一位能幹的 Microsoft 程式師查理斯·西蒙尼(Charles Simonyi) 提出的,他出生在匈牙利。在 Microsoft 公司中和他一起工作的人被教會使用這種約定。這對他們來說一切都很正常。但對那些 Simonyi 領導的項目組之外的人來說卻感到很奇特,他們認為這是死板的表達方式,甚至說代有這樣奇怪的外觀是因為它是用匈牙利文寫的。從此這種命名方式就被叫做匈牙利命名法。匈牙利命名法關鍵是:識別字的名字以一個或者多個小寫字母開頭作為首碼;首碼之後的是首字母大寫的一個單詞或多個單詞組合,該單詞要指明變數的用途。
匈牙利命名法中常用的小寫字母的字首
字首 |
類 型 |
a |
陣列 (Array) |
b |
布林值 (Boolean) |
by |
位元組 (Byte) |
c |
有符號字元 (Char) |
cb |
無符號字元 (Char Byte,沒有多少人用) |
cr |
顏色參考值 (ColorRef) |
cx,cy |
座標差(長度 ShortInt) |
d |
double |
dw |
Double Word |
fn |
函數 |
h |
Handle |
i |
整型 |
l |
長整數 (Long Int) |
lp |
Long Pointer |
m_ |
類的成員 |
n |
短整數 (Short Int) |
np |
Near Pointer |
p |
Pointer |
s |
字串型 |
sh |
Short |
sz |
以null做結尾的字串型 (String with Zero End) |
w |
Word |
但是在任何情況下,都硬性規定使用匈牙利命名法是迂腐的。尤其是 Unix 程式設計,在使用沒有變數名、關鍵字自動補齊功能的編輯器,如 vi 下,去敲入大小寫混合的變數名是痛苦的。其實只要注意兩個原則:
1) 含義清晰,不易混淆;
2) 不和其它模組、系統API的命名空間相衝突即可。
1.有意義的為變數名、巨集名加上本模組的關鍵字,就不至於和其它模組、系統API的命名空間相衝突;例如: 巨集的名稱過短,如:DEBUG; 或_DEBUG,很可能和別的模組,系統模組相衝突;
2.局部變數尤其是循環變數外,使用約定俗成的 i,j,k ,沒有問題;
3.巨集、常數、列舉enum,全部用大寫字母;
MFC、HANDLE、控件及結構的命名規範
Windows類型 |
樣本變數 |
MFC類 |
樣本變數 |
HWND |
hWnd; |
CWnd* |
pWnd; |
HDLG |
hDlg; |
CDialog* |
pDlg; |
HDC |
hDC; |
CDC* |
pDC; |
HGDIOBJ |
hGdiObj; |
CGdiObject* |
pGdiObj; |
HPEN |
hPen; |
CPen* |
pPen; |
HBRUSH |
hBrush; |
CBrush* |
pBrush; |
HFONT |
hFont; |
CFont* |
pFont; |
HBITMAP |
hBitmap; |
CBitmap* |
pBitmap; |
HPALETTE |
hPaltte; |
CPalette* |
pPalette; |
HRGN |
hRgn; |
CRgn* |
pRgn; |
HMENU |
hMenu; |
CMenu* |
pMenu; |
HWND |
hCtl; |
CState* |
pState; |
HWND |
hCtl; |
CButton* |
pButton; |
HWND |
hCtl; |
CEdit* |
pEdit; |
HWND |
hCtl; |
CListBox* |
pListBox; |
HWND |
hCtl; |
CComboBox* |
pComboBox; |
HWND |
hCtl; |
CScrollBar* |
pScrollBar; |
HSZ |
hszStr; |
CString |
pStr; |
POINT |
pt; |
CPoint |
pt; |
SIZE |
size; |
CSize | size; |
RECT |
rect; |
CRect |
rect; |
一般字首命名規範
首碼 |
類型 |
實例 |
C |
類或結構 |
CDocument,CPrintInfo |
m_ |
成員變數 |
m_pDoc,m_nCustomers |
g_ |
全域變數 |
|
c_ |
常數 |
|
變數命名規範
首碼 |
類型 |
描述 |
實例 |
ch |
char |
8位元字元 |
chGrade |
ch |
TCHAR |
如果_UNICODE定義,則為16位元字元 |
chName |
b |
BOOL |
布林值 |
bEnable |
n |
int |
整型(其大小依賴於作業系統) |
nLength |
n |
UINT |
無符號值(其大小依賴於作業系統) |
nHeight |
w |
WORD |
16位元無符號值 |
wPos |
l |
LONG |
32位元有符號整型 |
lOffset |
dw |
DWORD |
32位元無符號整型 |
dwRange |
p |
* |
指標 |
pDoc |
lp |
FAR* |
遠指標 |
lpszName |
lpsz |
LPSTR |
32位元字串指標 |
lpszName |
lpsz |
LPCSTR |
32位元常量字串指標 |
lpszName |
lpsz |
LPCTSTR |
如果_UNICODE定義,則為32位元常量字串指標 |
lpszName |
h |
handle |
Windows對象控制碼 |
hWnd |
lpfn |
callback |
指向CALLBACK函數的遠指標 |
|
應用程式符號命名規範
首碼 |
符號類型 |
實例 |
範圍 |
IDR_ |
不同類型的多個資源分享標識 |
IDR_MAIINFRAME |
1~0x6FFF |
IDD_ |
對話方塊資源 |
IDD_SPELL_CHECK |
1~0x6FFF |
HIDD_ |
對話方塊資源的Help上下文 |
HIDD_SPELL_CHECK |
0x20001~0x26FF |
IDB_ |
點陣圖資源 |
IDB_COMPANY_LOGO |
1~0x6FFF |
IDC_ |
游標資源 |
IDC_PENCIL |
1~0x6FFF |
IDI_ |
圖示資源 |
IDI_NOTEPAD |
1~0x6FFF |
ID_ |
來自功能表項或工具欄的命令 |
ID_TOOLS_SPELLING |
0x8000~0xDFFF |
HID_ |
命令Help上下文 |
HID_TOOLS_SPELLING |
0x18000~0x1DFFF |
IDP_ |
訊息方塊提示 |
IDP_INVALID_PARTNO |
8~0xDEEF |
HIDP_ |
訊息方塊Help上下文 |
HIDP_INVALID_PARTNO |
0x30008~0x3DEFF |
IDS_ |
串資源 |
IDS_COPYRIGHT |
1~0x7EEF |
IDC_ |
對話方塊內的控制項 |
IDC_RECALC |
8~0xDEEF |
Microsoft MFC 巨集命名規範
名稱 |
類型 |
_AFXDLL |
唯一的動態連接庫(Dynamic Link Library,DLL)版本 |
_ALPHA |
僅編譯DEC Alpha處理器 |
_DEBUG |
包括診斷的調試版本 |
_MBCS |
編譯多位元組字元集 |
_UNICODE |
在一個應用程式中打開Unicode |
AFXAPI |
MFC提供的函數 |
CALLBACK |
通過指標回調的函數 |
庫標識符命名法
識別字 |
值和含義 |
u |
ANSI(N)或Unicode(U) |
d |
調試或發行:D = 調試;忽略識別字為發行。 |
靜態庫版本命名規範
| 庫 | 描述 |
NAFXCWD.LIB |
除錯版本:MFC靜態連接庫 |
NAFXCW.LIB |
發行版本:MFC靜態連接庫 |
UAFXCWD.LIB |
除錯版本:具有Unicode支援的MFC靜態連接庫 |
UAFXCW.LIB |
發行版本:具有Unicode支援的MFC靜態連接庫 |
動態連結庫命名規範
名稱 |
類型 |
_AFXDLL |
唯一的動態連接庫(DLL)版本 |
WINAPI |
Windows所提供的函數 |
Windows.h中新的命名規範
類型 |
定義描述 |
WINAPI |
使用在API聲明中的FAR PASCAL位置,如果正在編寫一個具有導出API人口點的DLL,則可以在自己的API中使用該類型 |
CALLBACK |
使用在應用程式回叫常式,如視窗和對話方塊過程中的FAR PASCAL的位置 |
LPCSTR |
與LPSTR相同,只是LPCSTR用於唯讀串指標,其定義類似(const char FAR*) |
UINT |
可移植的無符號整型類型,其大小由主機環境決定(對於Windows NT和Windows 9x為32位);它是unsigned int的同義詞 |
LRESULT |
視窗程式返回值的類型 |
LPARAM |
聲明lParam所使用的類型,lParam是視窗程式的第四個參數 |
WPARAM |
聲明wParam所使用的類型,wParam是視窗程式的第三個參數 |
LPVOID |
一般指標類型,與(void *)相同,可以用來代替LPSTR |
這裏順便寫幾個例子:
hwnd : h 是類型描述,表示控制碼, wnd 是變數物件描述,表示視窗,所以 hwnd 表示視窗控制碼;
pfnEatApple : pfn 是類型描述,表示指向函數的指標, EatApple 是變數物件描述,所以它表示
指向 EatApple 函數的函數指標變數。
g_cch : g_ 是屬性描述,表示總體變數,c 和 ch 分別是計數類型和字元類型,一起表示變數類
型,這裏忽略了物件描述,所以它表示一個對字元進行計數的總體變數。
上面就是HN命名法的一般規則。
抨擊匈牙利命名法
匈牙利命名法是一種編程時的命名規範。命名規範是程式書寫規範中最重要也是最富爭議的地方,自古乃兵家必爭之地。命名規範有何用?四個字:名正言順。用二分法,命名規範分為好的命名規範和壞的命名規範,也就是說名正言順的命名規範和名不正言不順的命名規範。好的舞鞋是讓舞者感覺不到其存在的舞鞋,壞的舞鞋是讓舞者帶著鐐銬起舞。一個壞的命名規範具有的破壞力比一個好的命名規範具有的創造力要大得多。
證明匈牙利命名法是一個壞的命名規範
本文要證明的是:匈牙利命名法是一個壞的命名規範。本文的作用範圍為靜態強類型編程語言。本文的分析範本為C語言和C++語言。下文中的匈法為匈牙利命名法的簡稱。
匈牙利命名法的成本
匈法的表現形式為給變數名附加上類型名首碼,例如:nFoo,szFoo,pFoo,cpFoo分別表示整型變數,字串型變數,指標型變數和常指標型變數。可以看出,匈法將變數的類型資訊從單一地點(聲明變數處)複製到了多個地點(使用變數處),這是冗餘法。冗余法的成本之一是要維護副本的一致性。這個成本在編寫和維護代碼的過程中需要改變變數的類型時付出。冗余法的成本之二是佔用了額外的空間。一個優秀的書寫者會自覺地遵從一個法則:代碼最小組織單位的長度以30個自然行以下為宜,如果超過50行就應該重新組織。一個變數的書寫空間會給這一法則添加不必要的難度。
匈牙利命名法的收益
這裏要證明匈牙利命名法的收益是含糊的,無法預期的。
範本1:strcpy(pstrFoo,pcstrFoo2) Vs strcpy(foo,foo2)
匈法在這裏有什麼收益呢?我看不到。沒有一個程式師會承認自己不知道strcpy函數的參數類型吧。
範本2:unknown_function(nFoo) Vs unknown_function(foo)
匈法在這裏有什麼收益呢?我看不到。對於一個不知道確定類型的函數,程式師應該去查看該函數的文檔,這是一種成本。使用匈法的唯一好處是看代碼的人知道這個函數要求一個整型參數,這又有什麼用處呢?函數是一種介面,參數的類型僅僅是介面中的一小部分。諸如函數的功能、出口資訊、線程安全性、異常安全性、參數合法性等重要資訊還是必須查閱文檔。
範本3:nFoo=nBar Vs foo=bar
匈法在這裏有什麼收益呢?我看不到。使用匈法的唯一好處是看代碼的人知道這裏發生了一個整型變數的複製動作,聽起來沒什麼問題,可以安心睡大覺了。如果他看到的是nFoo=szBar,可能會從美夢中驚醒。且慢,事情真的會是這樣嗎?我想首先被驚醒的應該是編譯器。另一方面,nFoo=nBar只是在語法上合法而已,看代碼的人真正關心的是語義的合法性,匈法對此毫無幫助。另一方面,一個優秀的書寫者會自覺地遵從一個法則:代碼最小組織單位中的臨時變數以一兩個為宜,如果超過三個就應該重新組織。結合前述第一個法則,可以得出這樣的結論:易於理解的代碼本身就應該是易於理解的,這是代碼的內建高品質。好的命名規範對內建高品質的助益相當有限,而壞的命名規範對內建高品質的損害比人們想像的要大。
匈牙利命名法的實施
這裏要證明匈牙利命名法在C語言是難以實施的,在C++語言中是無法實施的。從邏輯上講,對匈法的收益做出否定的結論以後,再來論證匈法的可行性,是畫蛇添足。不過有鑒於小馬哥曾讓已射殺之敵死灰復燃,我還是再踏上一支腳為妙。
前面講過,匈法是類型系統的冗餘,所以實施匈法的關鍵是我們是否能夠精確地對類型系統進行複製。這取決於類型系統的複雜性。
先來看看C語言:
1.內置類型:int,char,float,double 複製為 n,ch,f,d?好像沒有什麼問題。不過誰來告訴我void應該怎麼表示?
2.組合類型:array,union,enum,struct 複製為 a,u,e,s?好象比較彆扭。
這裏的難點不是為主類型取名,而是為副類型取名。an表示整型陣列?sfoo,sbar表示結構foo,結構bar?ausfoo表示聯合結構foo陣列?累不累啊。
3.特殊類型:pointer。pointer在理論上應該是組合類型,但是在C語言中可以認為是內置類型,因為C語言並沒有非常嚴格地區分不同的指針類型。下面開始表演:pausfoo表示聯合結構foo陣列指標?ppp表示指針的指針的指針?
噩夢還沒有結束,再來看看類型系統更阿為豐富的C++語言:
1.class:如果說C語言中的struct還可以用stru搪塞過去的話,不要夢想用cls來搪塞C++中的class。嚴格地講,class根本就並不是一個類型,而是創造類型的工具,在C++中,語言內置類型的數量和class創造的用戶自定義類型的數量相比完全可以忽略不計。stdvectorFoo表示標準庫向量類型變數Foo?瘋狂的念頭。
2.命名空間:boostfilesystemiteratorFoo,表示boost空間filesystem子空間遍曆目錄類型變數Foo?程式師要崩潰了。
3.範本:你記得std::map<std::string,std::string>類型的確切名字嗎?我是記不得了,好像超過255個字元,還是饒了我吧。
4.範本參數:template <class T, class BinaryPredicate>const T& max(const T& a, const T& b, BinaryPredicate comp) 聰明的你,請用匈法為T命名。上帝在發笑。
參考文獻
周思博中提出:
想要瞭解匈牙利命名法的歷史背景, 可以由Simonyi的原文匈牙利命名法開始。 Doug Klunder在另一篇比較清楚的文章中把它引進Excel團體 。 想知道更多匈牙利命名法的故事以及如何被文件撰寫人破壞的始末, 可以去看Larry Osterman站上的貼文,特別是Scott Ludwig的評論,或是Rick Schaut貼的文章
參考:
http://dob.tnc.edu.tw/themes/old/showPage.php?s=1837&t=251
http://www.evanlin.com/blog/archives/000180.html
Joel on Software 周思博趣談軟體http://chinesetrad.joelonsoftware.com/Articles/Wrong.html
http://city.udn.com/v1/blog/article/article.jsp?uid=start8588&f_ART_ID=1171731
BugLu的專欄:http://blog.csdn.net/BugLu/archive/2006/07/21/953492.aspx
http://blog.programfan.com/article.asp?id=15658
Trackback: http://tb.blog.csdn.net/TrackBack.aspx?PostId=353883
http://blog.csdn.net/starway/archive/2005/04/19/353883.aspx
你願意做鐐銬上的舞者嗎?http://www.ieee.org.cn/dispbbs.asp?boardID=61&ID=25652
Simonyi的原文匈牙利命名法(http://msdn2.microsoft.com/en-us/library/Aa260976(VS.60).aspx)
Doug Klunder 把它引進Excel團體的文章(http://www.byteshift.de/msg/hungarian-notation-doug-klunder)
Larry Osterman(http://blogs.msdn.com/larryosterman/archive/2004/06/22/162629.aspx)
Scott Ludwig的評論(http://blogs.msdn.com/larryosterman/archive/2004/06/22/162629.aspx#163721)
Rick Schaut貼的文章(http://blogs.msdn.com/rick_schaut/archive/2004/02/14/73108.aspx)
Charles Petzold的視窗程式設計(http://www.charlespetzold.com/pw5/)